
Page 105 - AIH-1-2
P. 105
Artificial Intelligence in Health Schema-less text2sql conversion with LLMs
as the SQL queries generated from these questions often evaluating model performance by highlighting potential
involve multiple tables and columns. challenges associated with varying lengths. Understanding
these distributions is crucial for both effective selections
3.1.2. Size and partitioning of the model training hyperparameters, especially the
The MIMICSQL dataset comprises approximately 10,000 input and the output length, as well as assessment of the
examples, strategically partitioned into training and generalizability of the developed models to real-world
development (train and dev) sets, constituting 80% (8000 applications.
question-sql pairs), and a test set accounting for the 3.1.3. Challenges addressed
remaining 20% (2000 question-sql pairs). This division
facilitates both training and evaluation phases. Insights and One of the key challenges addressed by the MIMICSQL
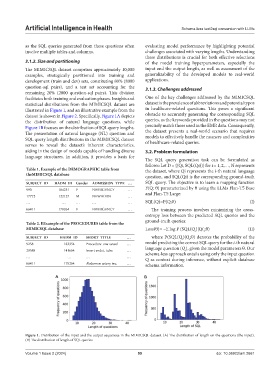
statistical distributions from the MIMICSQL dataset are dataset is the prevalence of abbreviations and potential typos
illustrated in Figure 1, and an illustrative example from the in healthcare-related questions. This poses a significant
dataset is shown in Figure 2. Specifically, Figure 1A depicts obstacle to accurately generating the corresponding SQL
the distribution of natural language questions, while queries, as the keywords provided in the questions may not
Figure 1B focuses on the distribution of SQL query lengths. precisely match those used in the EMR data. Consequently,
The presentation of natural language (NL) question and the dataset presents a real-world scenario that requires
SQL query length distributions in the MIMICSQL dataset models to effectively handle the nuances and complexities
serves to reveal the dataset’s inherent characteristics, of healthcare-related queries.
aiding in the design of models capable of handling diverse 3.2. Problem formulation
language structures. In addition, it provides a basis for
The SQL query generation task can be formulated as
follows: Let D = {(Qi, SQL(Qi))} for i = 1, 2,…, N represents
Table 1. Example of the DEMOGRAPHIC table from the dataset, where Qi represents the i-th natural language
theMIMICSQL database question, and SQL(Qi) is the corresponding ground-truth
SUBJECT_ID HADM_ID Gender ADMISSION_TYPE … SQL query. The objective is to learn a mapping function
990 184231 F EMERGENCY … F(Q; θ) parameterized by θ using the LLMs Flan-T5 Base
17772 122127 M NEWBORN … and Flan-T5 Large:
… … … … … SQL(Q)=F(Q;θ) (I)
66411 178264 F EMERGENCY … The training process involves minimizing the cross-
entropy loss between the predicted SQL queries and the
ground-truth queries:
Table 2. EExample of the PROCEDURES table from the
MIMICSQL database Loss(θ)= −∑ log P (SQL(Q )|Q( ;θ) (II)
i
i
SUBJECT_ID HADM_ID SHORT_TITLE … where P(SQL(Q )|Q ;θ) denotes the probability of the
i
i
9258 183354 Procedure-one vessel … model predicting the correct SQL query for the i-th natural
28588 141664 Insert endot. tube … language question (Q ), given the model parameters θ. Our
i
schema-less approach entails using only the input question
… … … … Q as context during inference, without explicit database
66411 178264 Abdomen artery inc. … schema information.
A B
Figure 1. Distribution of the input and the output sequences in the MIMICSQL dataset. (A) The distribution of length on the questions (the input).
(B) The distribution of length of SQL queries.
Volume 1 Issue 2 (2024) 99 doi: 10.36922/aih.2661