
Page 32 - AIH-1-4
P. 32
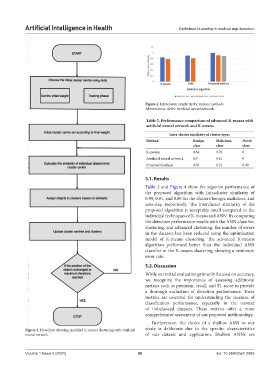
Artificial Intelligence in Health Optimized clustering in medical app detection
Figure 4. Intracluster similarity for various methods
Abbreviation: ANN: Artificial neural network.
Table 2. Performance comparison of advanced K‑means with
artificial neural network and K‑means
Intra‑cluster similarity of cluster types
Method Benign Malicious Novel
class class class
K-means 0.84 0.78 0
Artificial neural network 0.9 0.81 0
Proposed method 0.99 0.91 0.89
5.1. Results
Table 2 and Figure 4 show the superior performance of
the proposed algorithm with intracluster similarity of
0.99, 0.91, and 0.89 for the clusters benign, malicious, and
zero-day, respectively. The intercluster similarity of the
proposed algorithm is acceptably small compared to the
individual techniques of K-means and ANN. By comparing
the detection performance results with the ANN classifier,
clustering, and advanced clustering, the number of errors
in the datasets has been reduced using the optimization
model of K-means clustering. The advanced K-means
algorithm performed better than the individual ANN
classifier or the K-means clustering, showing a minimum
error rate.
5.2. Discussion
While our initial evaluation primarily focused on accuracy,
we recognize the importance of assessing additional
metrics such as precision, recall, and F1-score to provide
a thorough evaluation of detection performance. These
metrics are essential for understanding the nuances of
classification performance, especially in the context
of imbalanced datasets. These metrics offer a more
comprehensive assessment of our proposed methodology.
Furthermore, the choice of a shallow ANN in our
Figure 3. Flowchart showing modified K-means clustering with artificial study is deliberate due to the specific characteristics
neural network of our dataset and application. Shallow ANNs are
Volume 1 Issue 4 (2024) 26 doi: 10.36922/aih.2585