
Page 58 - AIH-2-2
P. 58
Artificial Intelligence in Health Predicting ICU mortality: A stacked ensemble model
additional improvement, with an F score slightly higher
1
than those of any single model.
Indicatively, CatBoost emerged as the top-performing
base model, achieving an F score of 0.935571 and a logloss
1
of 0.175849. LightGBM closely followed with an F score
1
of 0.935262 and a logloss of 0.178687, while XGBoost
delivered an F score of 0.93 and a logloss of 0.182571.
1
The important nature of the problem necessitated not
only great overall performance but also a careful balance
between limiting false positives and false negatives, even
if these models demonstrated high accuracy. Therefore,
we examined stacking ensemble learning further to
outperform any single model.
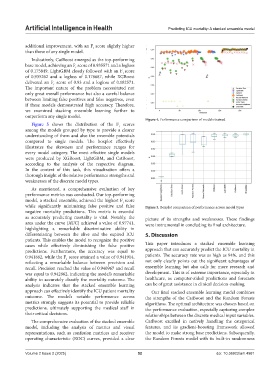
Figure 4. Performance comparison of models trained
Figure 5 shows the distribution of the F scores
1
among the models grouped by type to provide a clearer
understanding of them and also the ensemble potentials
compared to single models. The boxplot effectively
illustrates the skewness and performance ranges for
every model category. The most effective single models
were produced by XGBoost, LightGBM, and CatBoost,
according to the analysis of the respective diagram.
In the context of this task, this visualization offers a
thorough insight of the relative performance strengths and
weaknesses of the discrete model types.
As mentioned, a comprehensive evaluation of key
performance metrics was conducted. Our top-performing
model, a stacked ensemble, achieved the highest F score
1
while significantly minimizing false positive and false Figure 5. Boxplot comparison of performance across model types
negative mortality predictions. This metric is essential
as accurately predicting mortality is vital. Notably, the picture of its strengths and weaknesses. These findings
area under the curve (AUC) achieved a value of 0.97741, were instrumental in concluding its final architecture.
highlighting a remarkable discriminative ability in
differentiating between the alive and the expired ICU 5. Discussion
patients. This enables the model to recognize the positive
cases while effectively diminishing the false positive This paper introduces a stacked ensemble learning
predictions. Furthermore, the accuracy was equal to approach that can accurately predict the ICU mortality in
0.941882, while the F score attained a value of 0.941914, patients. The accuracy rate was as high as 94%, and this
1
reflecting a remarkable balance between precision and not only clearly points out the significant advantages of
recall. Precision reached the value of 0.940967 and recall ensemble learning but also calls for more research and
was equal to 0.942862, indicating the model’s remarkable development. This is of extreme importance, especially in
ability to accurately classify the mortality outcome. The healthcare, as computer-aided predictions and forecasts
analysis indicates that the stacked ensemble learning can be of great assistance in clinical decision-making.
approach can effectively identify the ICU patient mortality Our final stacked ensemble learning model combines
outcome. The model’s notable performance across the strengths of the CatBoost and the Random Forests
metrics strongly suggests its potential to provide reliable algorithms. The optimal architecture was chosen based on
predictions, ultimately supporting the medical staff in the performance evaluation, especially capturing complex
their critical decisions. relationships between the discrete medical input variables.
The comprehensive evaluation of the stacked ensemble CatBoost excelled in natively handling the categorical
model, including the analysis of metrics and visual features, and its gradient-boosting framework allowed
representations, such as confusion matrices and receiver the model to make strong base predictions. Subsequently,
operating characteristic (ROC) curves, provided a clear the Random Forests model with its built-in randomness
Volume 2 Issue 2 (2025) 52 doi: 10.36922/aih.4981