
Page 32 - AIH-2-4
P. 32
Artificial Intelligence in Health Early Parkinson’s detection through CNNs
A it has the inherent ability of feature selection and thereby
enhancing numerical stability. For neural network based
39
methods, dropout technique is used that involves randomly
dropping out a fraction of neurons during the training
process, thereby can help in preventing overfitting. 41
The hyperparameters of these methods are as follows:
• SVM: Regularization of parameter C.
• Logistic regression: Regularization of parameter C.
B
• CNN: Number of convolutional layers, number of
filters in each layer, filter sizes, dropout rate in each
layer, number of neurons in the fully connected layer,
dropout in the fully connected layer, batch size, and
number of epochs.
• MLP: Number of hidden layers, number of neurons in
each layer, and dropout rate.
C These hyperparameters were estimated using a hold-
out set (Partition 2, as explained in the above section),
while the models were trained and evaluated using the
normalized images from Partition 1 through a 10-fold
cross-validation approach.
2.6.1. CNNs for predictive modeling
In this work, a CNN model was created and trained to
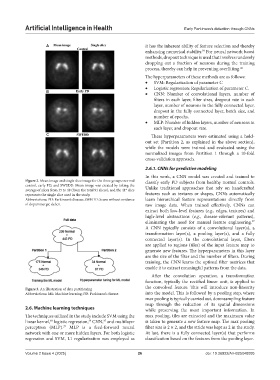
Figure 2. Mean image and single slice image for the three groups: normal classify early PD subjects from healthy normal controls.
control, early PD, and SWEDD. Mean image was created by taking the Unlike traditional approaches that rely on handcrafted
average of slices from 35 to 48 (from the total 91 slices), and the 41 slice
st
represents the single slice used in the study. features such as textures or shapes, CNNs automatically
Abbreviations: PD: Parkinson’s disease; SWEDD: Scans without evidence learn hierarchical feature representations directly from
of dopaminergic deficit. raw image data. When trained effectively, CNNs can
extract both low-level features (e.g., edges, textures) and
high-level abstractions (e.g., disease-relevant patterns),
eliminating the need for manual feature engineering.
37
A CNN typically consists of a convolutional layer(s), a
transformation layer(s), a pooling layer(s), and a fully
connected layer(s). In the convolutional layer, filters
are applied to regions (tiles) of the input feature map to
generate new features. The hyperparameters in this layer
are the size of the filter and the number of filters. During
training, the CNN learns the optimal filter matrices that
enable it to extract meaningful patterns from the data.
After the convolution operation, a transformation
function, typically the rectified linear unit, is applied to
Figure 3. An illustration of data partitioning the convolved feature. This will introduce non-linearity
Abbreviations: ML: Machine learning; PD: Parkinson’s disease. into the model. This is followed by a pooling step, where
max pooling is typically carried out, downsampling feature
map through the reduction of its spatial dimensions
2.6. Machine learning techniques while preserving the most important information. In
The techniques utilized in the study include SVM using the max pooling, tiles are extracted and the maximum value
linear kernel, logistic regression, CNN, and multilayer is taken to generate a new feature map. The max pooling
37
38
39
perceptron (MLP). MLP is a feed-forward neural filter size is 2 × 2, and the stride was kept as 2 in the study.
37
network with one or more hidden layers. For both logistic At last, there is a fully connected layer(s) that performs
regression and SVM, L1 regularization was employed as classification based on the features from the pooling layer.
Volume 2 Issue 4 (2025) 26 doi: 10.36922/AIH025040005