
Page 66 - AIH-2-4
P. 66
Artificial Intelligence in Health Synthetic data for obesity level prediction
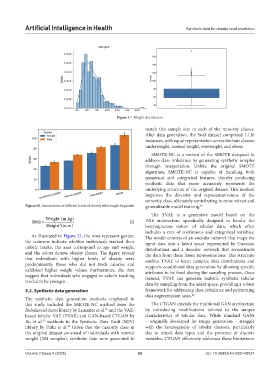
Figure 17. Weight distribution
match this sample size in each of the minority classes.
After data generation, the final dataset comprised 1,136
instances, with equal representation across the four classes:
underweight, normal weight, overweight, and obese.
SMOTE-NC is a variant of the SMOTE designed to
address class imbalance by generating synthetic samples
through interpolation. Unlike the original SMOTE
algorithm, SMOTE-NC is capable of handling both
numerical and categorical features, thereby producing
synthetic data that more accurately represents the
underlying structure of the original dataset. This method
improves the diversity and representativeness of the
minority class, ultimately contributing to more robust and
Figure 18. Associations of different levels of obesity with weight by gender generalizable model training. 39
The TVAE is a generative model based on the
Weight (in kg)
BMI = (I) VAE architecture, specifically designed to handle the
2
Height (in m) heterogeneous nature of tabular data, which often
includes a mix of continuous and categorical variables.
As illustrated in Figure 22, the rows represent gender, The model consists of an encoder network that maps the
the columns indicate whether individuals tracked their input data into a latent space represented by Gaussian
caloric intake, the axes correspond to age and weight, distributions and a decoder network that reconstructs
and the colors denote obesity classes. The figure reveals the data from these latent representations. This structure
that individuals with higher levels of obesity were enables TVAE to learn complex data distributions and
predominantly those who did not track calories and supports conditional data generation by allowing specific
exhibited higher weight values. Furthermore, the data attributes to be fixed during the sampling process. Once
suggest that individuals who engaged in calorie tracking trained, TVAE can generate realistic synthetic tabular
tended to be younger.
data by sampling from the latent space, providing a robust
3.2. Synthetic data generation framework for addressing class imbalance and performing
data augmentation tasks. 40
The synthetic data generation methods employed in
this study included the SMOTE-NC method from the The CTGAN extends the traditional GAN architecture
Imbalanced-learn library by Lemaître et al. and the VAE- by introducing modifications tailored to the unique
36
based tabular VAE (TVAE) and GAN-based CTGAN by characteristics of tabular data. While standard GANs
Xu et al. methods in the Synthetic Data Vault (SDV) – originally developed for image generation – struggle
37
library by Patki et al. Given that the majority class in with the heterogeneity of tabular datasets, particularly
38
the original dataset consisted of individuals with normal due to mixed data types and the presence of discrete
weight (284 samples), synthetic data were generated to variables, CTGAN effectively addresses these limitations.
Volume 2 Issue 4 (2025) 60 doi: 10.36922/AIH025140027