
Page 99 - AN-4-4
P. 99
Advanced Neurology Diffusion model for brain tumor classification
Softmaxx() expi x (VII) propagation, Adagrad, Adadelta, Adam, Adamax, and
i
k
ej x Nadam, with Adam ultimately selected for its balance
j 1
of computational efficiency and strong performance.
Hyperparameter optimization was conducted to (v) Dropout regularization: Both convolution and fully
fine-tune learning rates, batch sizes, and the number of connected layers were regularized using dropout
epochs. The Adam optimizer was used with a learning regularization with a dropout rate of 25%.
rate of 0.0001. The selection of hyperparameters in deep (vi) Loss function: The loss used was categorical cross-
deterministic decision-making models and CDDCNN is entropy to check whether the predicted probability
briefly described below. matches the true class output; hence, it enables the loss
(i) Learning rate: Learning rate was tested at values of to compare itself with the one-hot encoded labels and
0.0001, 0.001, 0.01, 0.1, and 0.2, with the optimal also makes the loss a multi-class classification.
learning rate of 0.0001 determined for CDCNN.
(ii) Batch size: Batch size is the number of samples that are An 80/20 split was applied to the dataset for training and
processed before any weight update, and was tested at testing. The model was trained for 50 epochs with a batch
10–100; the optimal batch size was 32. size of 32. The integration of synthetic datasets from DDM
(iii) Epochs number: This is the number of times that the significantly enhanced the performance metrics, ensuring
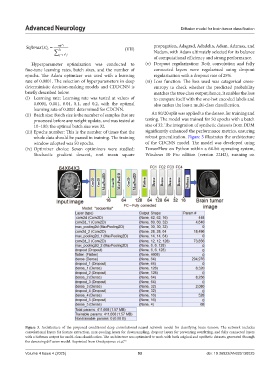
whole data should be passed in training. The training robust generalization. Figure 3 illustrates the architecture
window adopted was 50 epochs. of the CDCNN model. The model was developed using
(iv) Optimizer choice: Seven optimizers were studied: TensorFlow on Python within a 64-bit operating system,
Stochastic gradient descent, root mean square Windows 10 Pro edition (version 22H2), running on
Figure 3. Architecture of the proposed conditional deep convolutional neural network model for classifying brain tumors. The network includes
convolutional layers for feature extraction, max-pooling layers for downsampling, dropout layers for preventing overfitting, and fully connected layers
with a Softmax output for multi-class classification. The architecture was optimized to work with both original and synthetic datasets generated through
the denoising diffusion model. Reprinted from Onakpojeruo et al. 52
Volume 4 Issue 4 (2025) 93 doi: 10.36922/AN025130025