
Page 54 - MSAM-2-1
P. 54
Materials Science in Additive Manufacturing Data imputation strategies of PBF Ti64
A B C
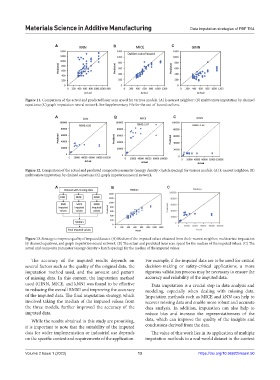
Figure 11. Comparison of the actual and predicted laser scan speed for various models. (A) k-nearest neighbor; (B) multivariate imputation by chained
equations; (C) graph imputation neural network. See Supplementary File for the out-of-bound outliers.
A B C
Figure 12. Comparison of the actual and predicted composite parameter (energy density × hatch spacing) for various models. (A) k-nearest neighbor; (B)
multivariate imputation by chained equations; (C) graph imputation neural network.
A B C
Figure 13. Strategy to improve quality of imputed dataset. (A) Median of the imputed values obtained from the k-nearest neighbor, multivariate imputation
by chained equations, and graph imputation neural network. (B) The actual and predicted laser scan speed for the median of the imputed values. (C) The
actual and composite parameter (energy density × hatch spacing) for the median of the imputed values.
The accuracy of the imputed results depends on For example, if the imputed data are to be used for critical
several factors such as the quality of the original data, the decision-making or safety-critical applications, a more
imputation method used, and the amount and pattern rigorous validation process may be necessary to ensure the
of missing data. In this context, the imputation method accuracy and reliability of the imputed data.
used (GINN, MICE, and kNN) was found to be effective Data imputation is a crucial step in data analysis and
in reducing the overall RMSE and improving the accuracy modeling, especially when dealing with missing data.
of the imputed data. The final imputation strategy, which Imputation methods such as MICE and kNN can help to
involved taking the median of the imputed values from recover missing data and enable more robust and accurate
the three models, further improved the accuracy of the data analysis. In addition, imputation can also help to
imputed data. reduce bias and increase the representativeness of the
While the results obtained in this study are promising, data, which can improve the quality of the insights and
it is important to note that the suitability of the imputed conclusions derived from the data.
data for wider implementation or industrial use depends The value of this work lies in its application of multiple
on the specific context and requirements of the application. imputation methods to a real-world dataset in the context
Volume 2 Issue 1 (2023) 13 https://doi.org/10.36922/msam.50