
Page 128 - AIH-1-3
P. 128
Artificial Intelligence in Health Interpretability of deep models for COVID-19
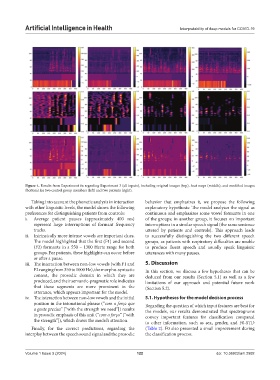
Figure 4. Results from Experiment 6a regarding Experiment 3 (all inputs), including original images (top), heat maps (middle), and modified images
(bottom) for two control group members (left) and two patients (right).
Taking into account the phonetic analysis in interaction behavior that emphasizes it, we propose the following
with other linguistic levels, the model shows the following explanatory hypothesis: The model analyzes the signal as
preferences for distinguishing patients from controls: continuous and emphasizes some vowel formants in one
i. Average patient pauses (approximately 400 ms) of the groups; in another group, it focuses on important
represent large interruptions of formant frequency interruptions in a similar speech signal (the same sentence
tracks. uttered by patients and controls). This approach leads
ii. Intrinsically more intense vowels are important clues. to successfully distinguishing the two different speech
The model highlighted that the first (F1) and second groups, as patients with respiratory difficulties are unable
(F2) formants in a 550 – 1300 Hertz range for both to produce fluent speech and usually speak linguistic
groups. For patients, these highlights can occur before utterances with many pauses.
or after a pause.
iii. The interaction between non-low vowels (with F1 and 5. Discussion
F2 ranging from 350 to 1000 Hz), the morpho-syntactic In this section, we discuss a few hypotheses that can be
context, the prosodic domain in which they are deduced from our results (Section 5.1) as well as a few
produced, and their semantic-pragmatic role indicates limitations of our approach and potential future work
that these segments are more prominent in the (Section 5.2).
utterance, which appears important for the model.
iv. The interaction between non-low vowels and the initial 5.1. Hypotheses for the model decision process
position in the intonational phrase (“com a força que Regarding the question of which input features are best for
a gente precisa” [“with the strength we need”]) results the models, our results demonstrated that spectrograms
in prosodic emphasis of this unit (“com a força” [“with convey important features for classification compared
the strength”]), which draws the model’s attention. to other information, such as sex, gender, and F0-STD
Finally, for the correct predictions, regarding the (Table 2). F0 also presented a small improvement during
interplay between the speech sound signal and the prosodic the classification process.
Volume 1 Issue 3 (2024) 122 doi: 10.36922/aih.2992