
Page 77 - AIH-2-4
P. 77
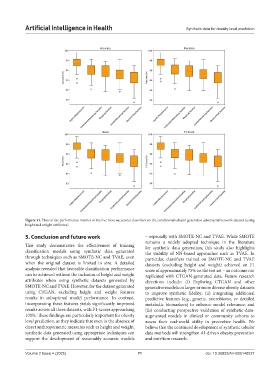
Artificial Intelligence in Health Synthetic data for obesity level prediction
Figure 31. Plots of the performance metrics of the five most successful classifiers on the conditional tabular generative adversarial network dataset (using
height and weight attributes)
5. Conclusion and future work – especially with SMOTE-NC and TVAE. While SMOTE
remains a widely adopted technique in the literature
This study demonstrates the effectiveness of training for synthetic data generation, this study also highlights
classification models using synthetic data generated the viability of NN-based approaches such as TVAE. In
through techniques such as SMOTE-NC and TVAE, even particular, classifiers trained on SMOTE-NC and TVAE
when the original dataset is limited in size. A detailed datasets (excluding height and weight) achieved an F1
analysis revealed that favorable classification performance score of approximately 75% on the test set – an outcome not
can be achieved without the inclusion of height and weight replicated with CTGAN-generated data. Future research
attributes when using synthetic datasets generated by directions include: (i) Exploring CTGAN and other
SMOTE-NC and TVAE. However, for the dataset generated generative models on larger or more diverse obesity datasets
using CTGAN, excluding height and weight features to improve synthetic fidelity; (ii) integrating additional
results in suboptimal model performance. In contrast, predictive features (e.g., genetic, microbiome, or detailed
incorporating these features yields significantly improved metabolic biomarkers) to enhance model relevance; and
results across all three datasets, with F1-scores approaching (iii) conducting prospective validation of synthetic-data-
100%. These findings are particularly important for obesity augmented models in clinical or community cohorts to
level prediction, as they indicate that even in the absence of assess their real-world utility in preventive health. We
direct anthropometric measures such as height and weight, believe that the continued development of synthetic tabular
synthetic data generated using appropriate techniques can data methods will strengthen AI-driven obesity prevention
support the development of reasonably accurate models and nutrition research.
Volume 2 Issue 4 (2025) 71 doi: 10.36922/AIH025140027