
Page 76 - AIH-2-4
P. 76
Artificial Intelligence in Health Synthetic data for obesity level prediction
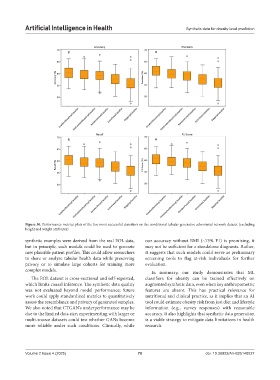
Figure 30. Performance metrics plots of the five most successful classifiers on the conditional tabular generative adversarial network dataset (excluding
height and weight attributes)
synthetic examples were derived from the real EOL data, our accuracy without BMI (~75% F1) is promising, it
but in principle, such models could be used to generate may not be sufficient for a standalone diagnosis. Rather,
new plausible patient profiles. This could allow researchers it suggests that such models could serve as preliminary
to share or analyze tabular health data while preserving screening tools to flag at-risk individuals for further
privacy or to simulate large cohorts for training more evaluation.
complex models. In summary, our study demonstrates that ML
The EOL dataset is cross-sectional and self-reported, classifiers for obesity can be trained effectively on
which limits causal inference. The synthetic data quality augmented synthetic data, even when key anthropometric
was not evaluated beyond model performance; future features are absent. This has practical relevance for
work could apply standardized metrics to quantitatively nutritional and clinical practice, as it implies that an AI
assess the resemblance and privacy of generated samples. tool could estimate obesity risk from just diet and lifestyle
We also noted that CTGAN’s underperformance may be information (e.g., survey responses) with reasonable
due to the limited data size; experimenting with larger or accuracy. It also highlights that synthetic data generation
multi-source datasets could test whether GANs become is a viable strategy to mitigate data limitations in health
more reliable under such conditions. Clinically, while research.
Volume 2 Issue 4 (2025) 70 doi: 10.36922/AIH025140027